Houdini
Revisiting Parallel Transport
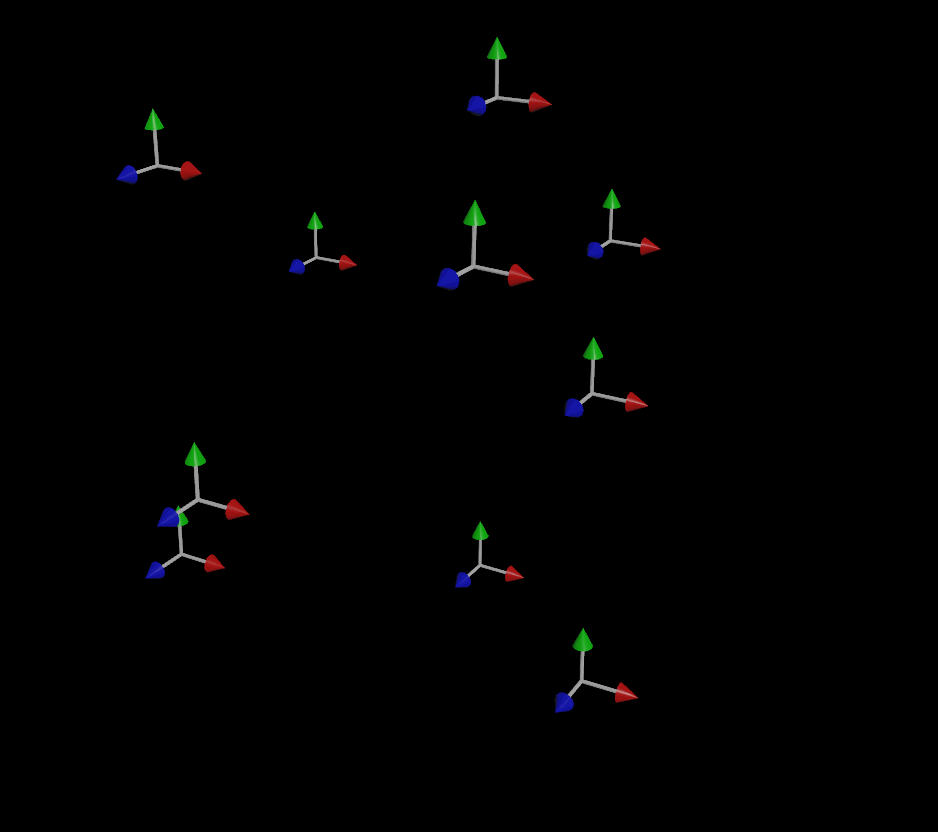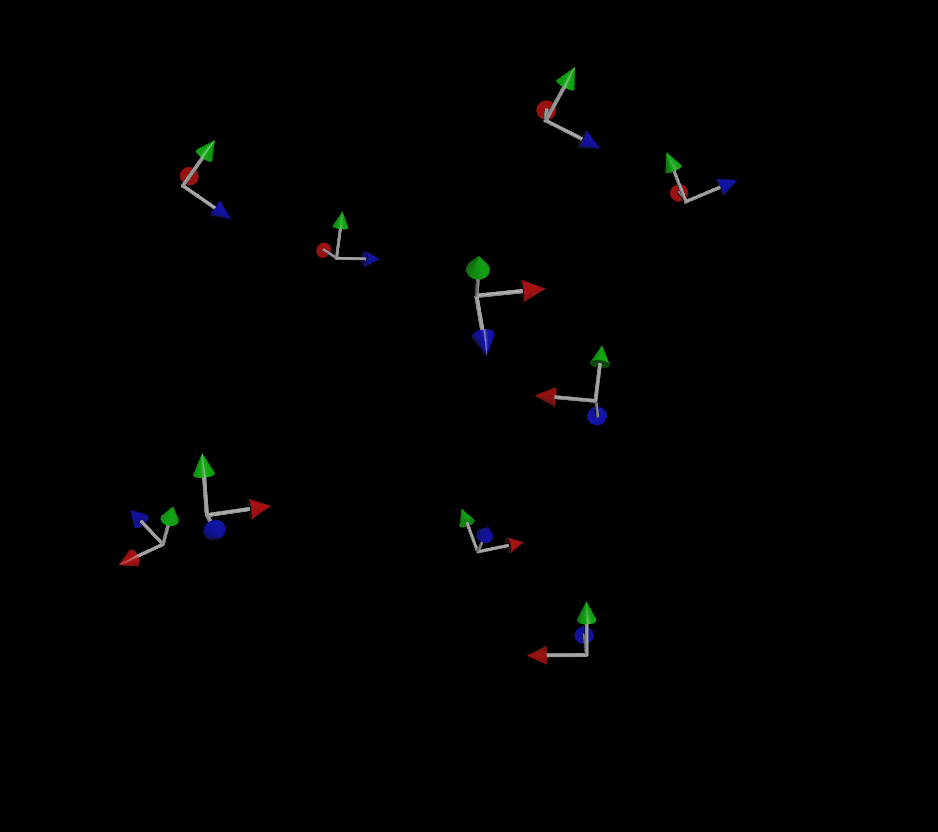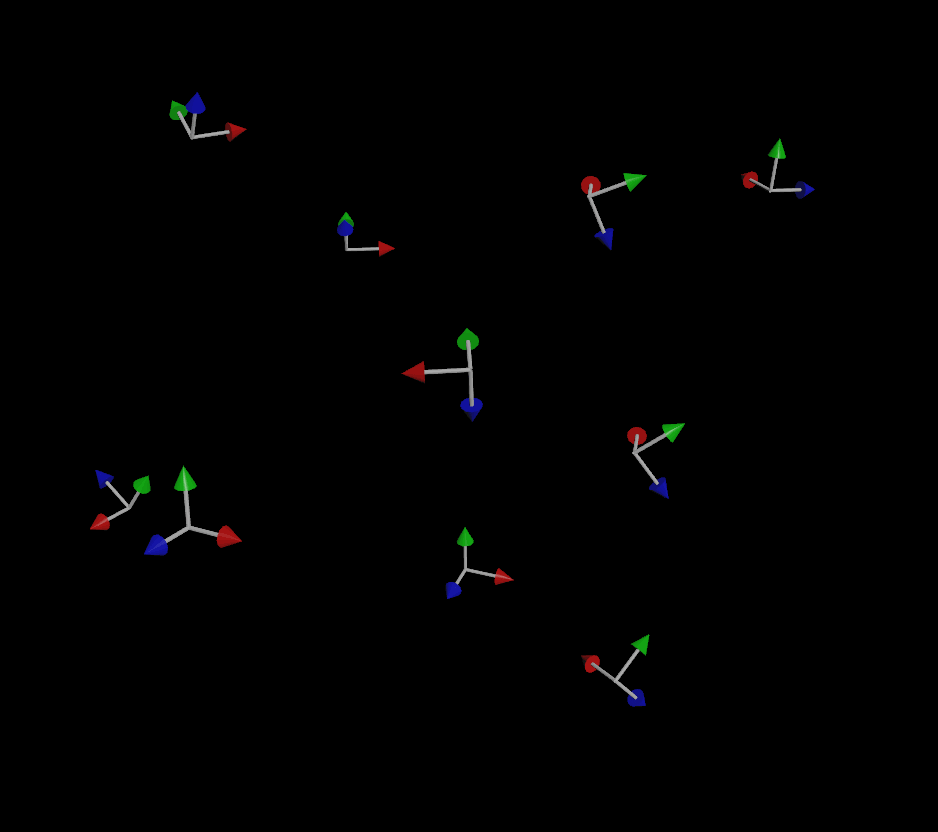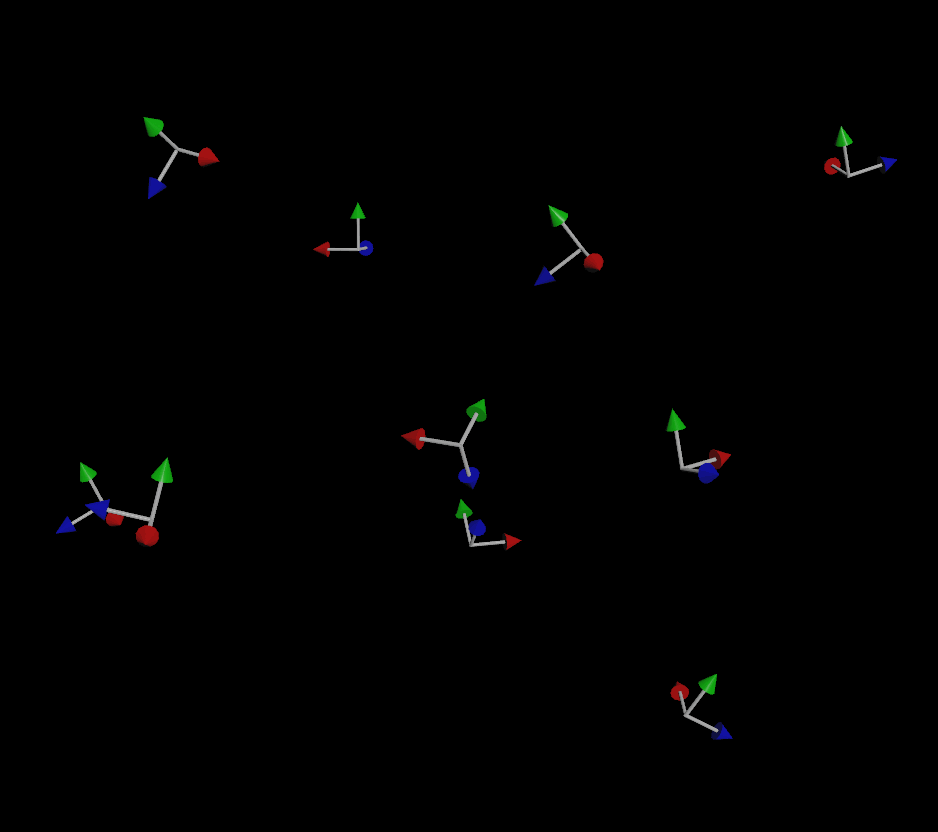
I was asked the other day about fixing a little issue with MOPs Orient Curve, a node that really hasn’t changed much in MOPs since it was first launched way back in 2018. Most of the reason it hasn’t been Read more…